
Talegenkendelse er komplekst. Talegenkendelse bygger på sprogteorier, statistiske antagelser og datalogiske muligheder. Det kræver, at man for at forstå talegenkendelse detaljeret skal have forstand på signalbehandling, akustik, maskinlæring, datalogi, statistik, fonetik, grammatik mm.
Dette er den første artikel i en række, der skal forklare hvordan talegenkendelse virker og hvorfor. Der er meget få ressourcer på dansk for netop dette felt, hvilket bliver mere problematisk som talegenkendelse bliver en større del af hverdagen.
Hvad er heteroscedastic linear discriminant analysis?!?
Kort fortalt: Det er en metode til finde de værdier, der bedst beskriver et datapunkt. Dvs. hvis et datapunkt beskrives af 700 værdier kan man bruge denne metode til at sortere de unødvendige værdier fra [1, v1].
Et af formålene med artikelserien er at rydde op i forkortelser og fagtermer. De bliver ofte brugt i flæng af sælgere, teknikere og forskere. Et godt eksempel er termerne fon og fonem. De størrelser er centrale i de lingvistiske discipliner fonetik og fonologi. Et fonem er et symbol, der beskrives som 'det mindste betydningsadskillende element' [2]. En fon er et symbol for en lyd, der forekommer i et sprog, f.eks. dansk. Forskellen er bl.a., at en fon ikke altid er betydningsadskillende og at et fonem kan udtales forskelligt. Altså kan et fonem's udtale repræsenteres med forskellige foner. De foner, der kan repræsentere et fonem, kaldes allofoner [3, v2].
Forskellen mellem en fon og et fonem er ikke altid nem at forstå for dataloger, ingeniører, matematikere eller grammatikere og bliver derfor ofte brugt 'forkert' ifølge fonetikere/fonologer. Det leder til en masse misforståelse.
Hvor kan jeg finde mere information?
Der er 2 slags links herover f.eks. med navnene '1' og 'v1'. Hvis vi kan finde yderligere materiale vil vi indsætte dem således. Hvis vi henviser til videnskabelige artikler vil linknavnet inkludere et 'v'. Derudover vil der nogle gange i disse artikler være en Detalje-sektion, hvor vi forklarer metoder og teorier mere dybdegående. Henvisningerne vil i mange tilfælde være på engelsk, da der ikke findes mange ressourcer på dansk.
Klassisk oversigt over talegenkendelsessystem
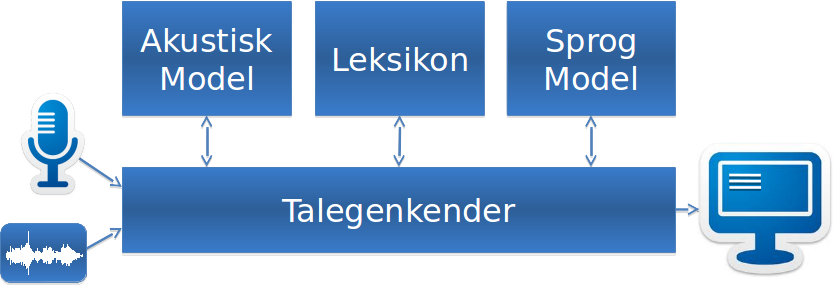 |
| Konceptuelt overbliksbillede |
Herover er de vigtigste komponenter i et talegenkendelsessystem vist. En talegenkender består altid af 4 kernekomponenter:
- Frontend: behandler lydsignalet fra mikrofonen
- Akustisk model: klassificerer den behandlede lyd i foner
- Leksikon: en ordbog der oversætter foner til ord
- Sprogmodel: en grammatisk model der danner den mest sandsynlige sætning
Detaljer
En god gennemgang på engelsk af talegenkendelse kan findes i Language and Speech processing af Jurafsky og Martin [v3]. Det er en grundbog brugt for uddannelser i datalingvistik, sprogteknologi og natursprogsprocessering (eng: computational linguistics, language technology, natural language processing).
En anden ofte brugt kilde er HTKbook [v4]. Det er en ældre tilgang, men forudsætter derfor mindre forhåndsviden.
Software
HTK (Hidden Markov model Toolkit) har længe været brugt til at lave talegenkendelsessystemer. Herunder er en liste af de mest kendte åbne tool kits:
Der er selvfølgelig også kommercielle systemer fra firmaer som Nuance Communications, IBM, Google, Microsoft, AT&T og der er forlydender om, at Apple er på vej med deres eget system. Apple har tidligere brugt Nuance-produkter til talegenkendelse.
Fon/fonem
Hvis man stadig er i tvivl om distinktionen mellem foner og fonemer kan man læse f.eks. Fonetik og Fonologi af Nina Grønnum. Det er en grundbog i dansk lingvistik. Ellers er schwa.dk også en god ressource til dansk fonetik. Indehaveren, Ruben Schactenhaufen, er også god til at svare på spørgsmål.