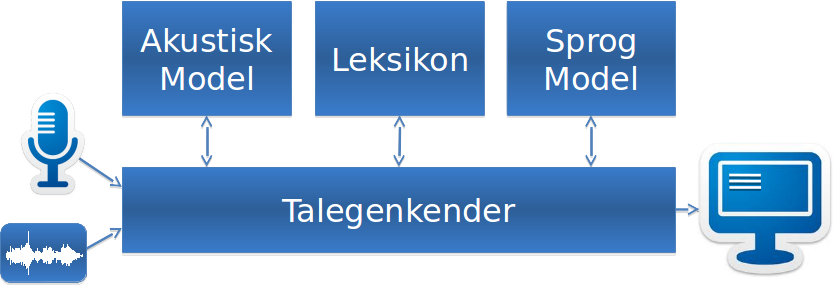
Som nævnt i de tidligere blogartikler skal lydsignalet behandles inden det kan bruges som input til talegenkendelsessoftware. Den behandling omfatter
De sorte sværtninger kaldes formanter. En formant er en del af frekvensbåndet, hvor der er meget energi og repræsenterer tonehøjde i vores eksempel. I et spektrum for en anden fon, f.eks. [e] i der vil formanterne placere sig anderledes:
Læg mærke til, at bl.a. de to nederste formanter ligger tættere, mens den øverste formant fra [i]-fonen er mere tydelig end den øverste formant fra [e] i der. Et tværsnit af et spektrum viser en profil af den fon, der er blevet udtalt på det tidspunkt. Herunder er profilerne for fonerne [i] og [e]:
De to profiler er tydeligt forskellige. Ofte er forskellen mellem sonoranter, dvs. alle foner man kan 'synge' på såsom vokaler, men også [n], [m] og [l], tydeligst i de høje formanter, altså til højre i profilerne. Menneskeøret er dog mindst følsomt overfor formanter i høje frekvensbånd. Derfor filtrerer man et spektrum med en såkaldt Mel-filterbank[3]. 20-40 filtre ændrer et spektrum, så der tages højde for den frekvensmæssigt ulige følsomhed af det menneskelige øre[4].
Hvert spektrum skal konverteres til et cepstrum[5]. Et cepstrum er et spektrum-af-et-spektrum. I et cepstrum kan man adskille det man kalder kilden og filteret[6,v5] . I TGK er man interesseret i de værdier som parametriserer filteret, da de værdier ændres, alt efter hvilken fon er udtalt.
Fra et cepstrum udtrækker man 12 koefficienter. Disse koefficienter sammen med et parameter for den samlede energi i lydvinduet udgør 13 parametre. For at tage højde for udviklingen af de parametre over tid tilføjer man både den første og anden afledede funktion af alle parametre til at modellere henholdsvis hastighed og acceleration. Det resulterer i de 39 parametre i MFCC feature vectors.
- Digitalisering af det analoge lydsignal og
- Konvertering af den digitale optagelse til et format som TGK-software kan bruge
Digitalisering af lyd
Digitalisering er den samme process som optagelse af enhver anden lyd til en lydfil. Lyd kan fysisk forklares som lydbølger eller små forskelle i lufttryk. I en mikrofon sidder en trykfølsom membran, som kan registrere disse forskelle. Det giver en lydbølge[1] over tid som den herunder:
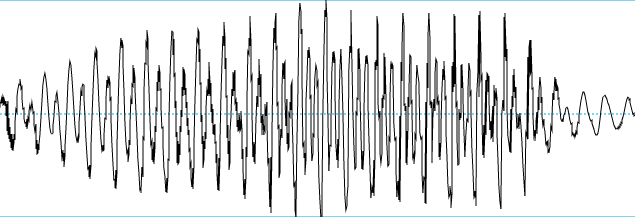 |
| Lydbølge for fonen [i] fra udtale af ordet cirkel |
Linien i midten svarer til '0' eller neutral stilling for membranen i mikrofonen. Dvs. der ikke er registreret nogen ændring i lufttrykket. Det viser også, at både højere og lavere lufttryk registreres.
Udtalemæssigt er ændringen i lufttryk skabt af stemmelæberne[2] som i eksemplet herover svinger periodisk. Man kan se mod slutningen af lydbølgen, at de periodiske svingninger ændres ved udtalen af [r]-fonen og til sidst forsvinder periodiciteten på vej ind i [k]-fonen.
På computere kan man ikke behandle et kontinuerligt signal og derfor sampler man lydsignalet. I denne kontekst er et sample en måling af udsvinget af lydsignalet, så man konverterer altså lydsignalet til en sekvens af samples. Man skal sample (måle) i tilstrækkeligt små intervaller til, at man kan estimere det originale lydsignal fra de samples, man har målt. Så jo flere samples, des bedre er lydgengivelsen[v1] .
Normale sample rates er f.eks. 44100 Hz, 16000 Hz og 8000 Hz, hvor lydgengivelsen er bedst ved 44100 Hz. Det skal opvejes mod størrelsen af lydfilerne. 44100 Hz sample rate betyder, at man sampler 44100 gange i sekundet, hvilket giver store datamængder, som er tunge at processere senere i TGK-systemer. Ofte bruger man derfor 16000 Hz eller 8000 Hz sample rate.
Feature extraction
Feature extraction er navnet på den process, der konverterer et digitalt lydsignal til input til TGK-systemer. Den digitale lydoptagelse, som er en sekvens af samples, skal konverteres til en sekvens af feature vectors. En vector (DA: vektor) er en liste af parametre og i en feature vector kaldes de parametre features.
Der er flere metoder til at udtrække features fra en digital lydoptagelse såsom Mel-Feature Cepstral Coefficients (MFCC)[v2], Linear Prediction Coefficients (LPC)[v3] og Perceptual Linear Prediction (PLP)[v4] coefficients. Den mest udbredte feature extraction-metode er MFCC extraction.
I MFCC extraction skal man sample en lydfil. Hver sample vil repræsentere 10-25ms lydvinduer kaldet sample-vinduet. Udover sample-vinduets størrelse er forskellen ved denne sampling, at sample-vinduet kan rykke sig mindre end vinduet i hver sampling, så der er en smule overlap mellem målingerne som vist herunder:
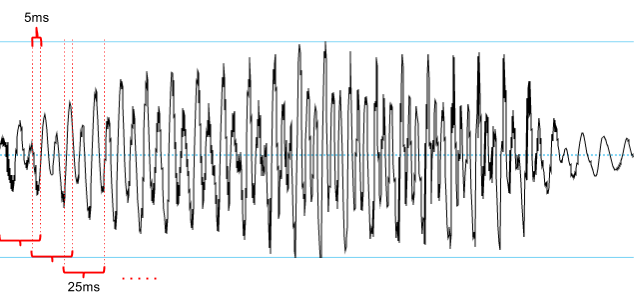 |
| 25 ms sample-vindue med et ryk på 20 ms resulterer i 5 ms overlap |
For hvert sample udregner man et spektrum. Et spektrum af det løbende eksempel kan ses her:
 |
| Spektrum for fonen [i] fra udtale af ordet cirkel |
 |
| Spektrum for fonen [e] fra udtale af ordet der |
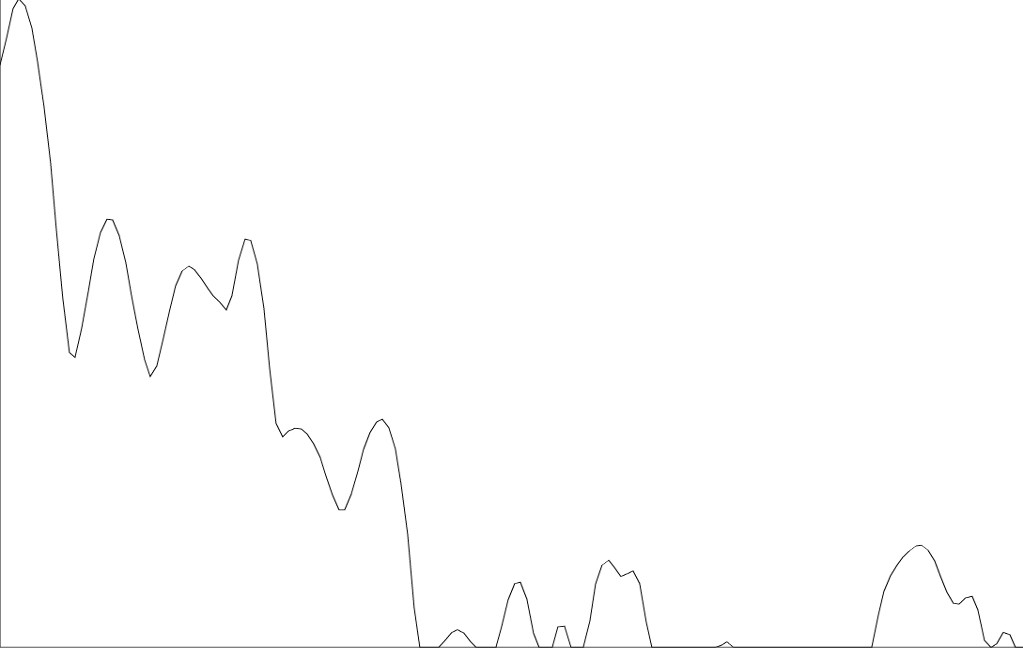 |
| Spektral profil for [i] |
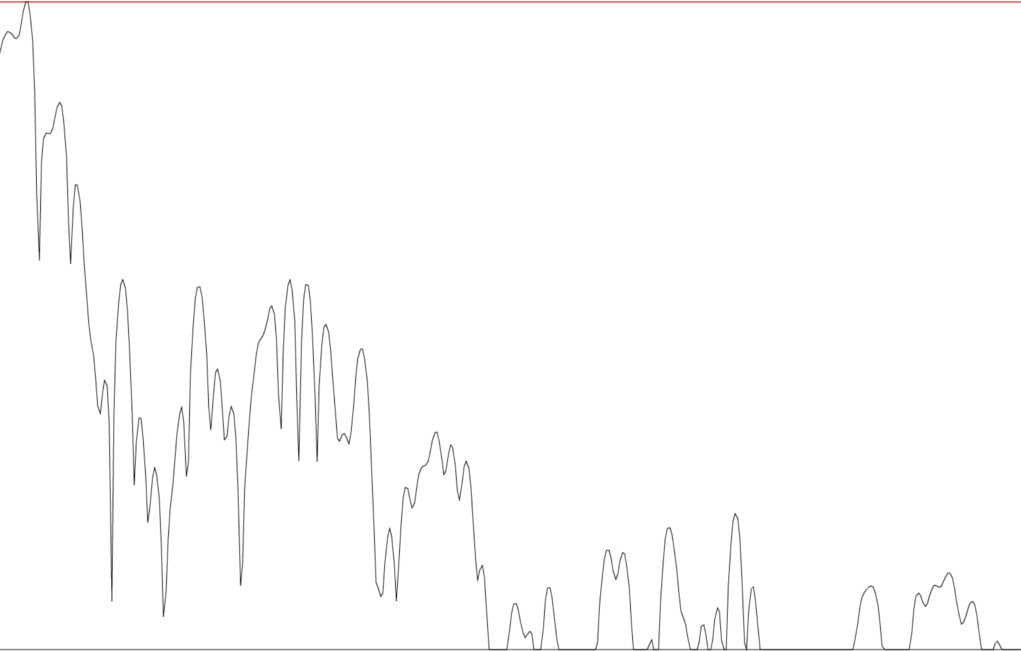 |
| Spektral profil for [e] |
De to profiler er tydeligt forskellige. Ofte er forskellen mellem sonoranter, dvs. alle foner man kan 'synge' på såsom vokaler, men også [n], [m] og [l], tydeligst i de høje formanter, altså til højre i profilerne. Menneskeøret er dog mindst følsomt overfor formanter i høje frekvensbånd. Derfor filtrerer man et spektrum med en såkaldt Mel-filterbank[3]. 20-40 filtre ændrer et spektrum, så der tages højde for den frekvensmæssigt ulige følsomhed af det menneskelige øre[4].
Hvert spektrum skal konverteres til et cepstrum[5]. Et cepstrum er et spektrum-af-et-spektrum. I et cepstrum kan man adskille det man kalder kilden og filteret[6,v5] . I TGK er man interesseret i de værdier som parametriserer filteret, da de værdier ændres, alt efter hvilken fon er udtalt.
 |
| Cepstrum for vokalen [i] |
Fra et cepstrum udtrækker man 12 koefficienter. Disse koefficienter sammen med et parameter for den samlede energi i lydvinduet udgør 13 parametre. For at tage højde for udviklingen af de parametre over tid tilføjer man både den første og anden afledede funktion af alle parametre til at modellere henholdsvis hastighed og acceleration. Det resulterer i de 39 parametre i MFCC feature vectors.
Detaljer
Alle billeder i denne blogartikel er lavet vha. Praat[7]. Det er et godt visualiseringsværktøj og kan også udtrække både MFCC- og LPC-vektorer.Nyquist sampling teorem[8]
Hvis man antager, at den højeste frekvenskomponent i et lydsignal er 3000 Hz, skal sampling-frekvensen (hvor ofte man måler signalet) være minimum 2 * den højeste frekvenskomponent, hvilket er 6000 Hz. Mest information om foner er koncentreret i de lave frekvenser omkring 4000 Hz og under, hvilket gør det muligt at nøjes med en sample rate på 8000 Hz. Det er dog et minimum og ved en uheldig sampling kan det være umuligt at genskabe det originale kontinuerlige signal. For at undgå det problem plejer man derfor at bruge 16000 Hz sample rates til TGK.
Pre-emphasis
I tale er mest energi koncentreret i de lave frekvensbånd, men energien i de høje frekvensbånd er signifikante for at klassificere sonoranter. For at forbedre fonklassificering booster man energien i de høje frekvensbånd, inden man udregner et spektrum.
Fourier transformation
Udregningen af et spektrum kaldes en Fourier-transformation[9] eller Fourier-analyse. Fourier-analysen er implementeret på forskellige måder, men oftest, da man i TGK er interesseret i at processering skal foregå så tæt på realtid som muligt, bruger man algoritmen Fast Fourier Transform (FFT)[10].Mel-filterbank
Menneskets følsomhed overfor toner er lineær under 1000 Hz, men logaritmisk over 1000 Hz. Melskalaen presser i praksis den højre del af de spektrale profiler sammen og skaber en mindre afstand mellem formanterne i de høje frekvensbånd. Der er mellem 20 og 40 filtre i en mel-filterbank og derfor er der mellem 20 og 40 parametre efter melfiltrering.Log
Efter filtrering til melskalaen tager man logaritmen af de spektrale værdier. Det gør værdierne mere robuste ved senere processering.
Cepstrum
Ordet cepstrum kommer af at bytte om på bogstaverne i det engelske ord spectrum (s-p-e-c-trum => c-e-p-s-trum). Antallet af koefficienter eller parametre i et cepstrum afhænger af antallet af melfiltre. Eksperimenter har vist, at den første koefficient er følsom overfor f.eks. talerens afstand til mikrofonen og hvor højt vedkommende taler. Den første koefficient ignoreres derfor og de efterfølgende 12 koefficienter gemmes.
Kontekst-afhængighed
Parametrene i MFCC-vektorer varierer langsomt over tid, hvilket gør det unødvendigt at tage højde for kontekst-afhængighed. Den antagelse holder i stor udstrækning, men tager ikke højde for koartikulationseffekter[v6], som kan have en effekt på udtalen i et større tidsperspektiv, dvs. på tværs af foner. Et eksempel er udtalen af [n] i munde og i minde. Udtalen af [n] er forskellig, fordi den er 'farvet' af artikulationen af den foranstående vokal. Med overtydelig artikulation kan man for sig selv illustrere, at læbernes position under udtale af [n] afhænger af læbernes position under udtale af henholdsvis [i] eller [u].
For at tage højde for koartikulation bruger man ofte Linear Discriminant Analysis (LDA) til at transformere MFCC (eller LPC) parametre. En klassisk tilgang er at tage et kontekstvindue, f.eks. +/- 5 MFCC-vektorer til i alt 11 vektorer og konkatenere vektorerne sammen til én vektor med 429 (11*39) parametre og derefter bruger man LDA til at reducere antallet af parametre til f.eks. 40 parametre. Antallet af parametre efter analysen skal specificeres inden bergningerne starter. LDA-analysen finder de vigtigste parametre ved at udregne, hvilke parametre minimerer variansen af en underliggende gaussiske distribution og hvilke parametre maximerer adskillelsen af foner.
Da forklaringen af LDA hænger meget sammen med den akustiske model. Yderligere detaljer om LDA udskydes til den artikel sammen med gennemgang af Dybe Neurale Net (DNN).